Boson AI 与 SGLang-Omni 团队近日宣布,Higgs Audio v3 TTS 模型已在 SGLang-Omni 框架上实现端到端部署。该模型专为对话式语音代理设计,能以低延迟生成自然且富有表现力的语音,支持 100 种语言且 WER/CER 保持个位数,同时允许开发者通过输入文本流直接控制情感、风格、韵律和音效。
专为真实对话设计的 TTS 模型
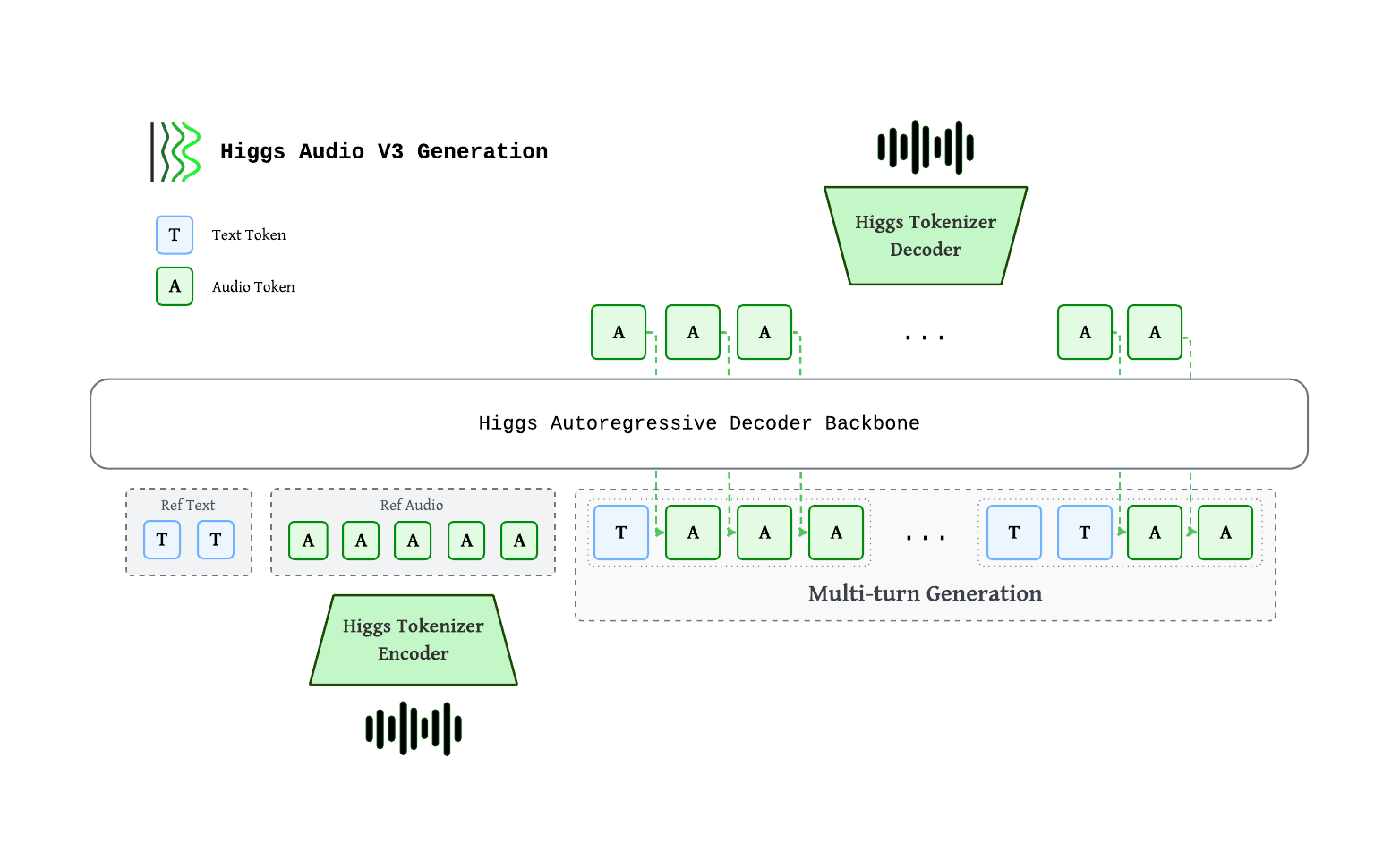
Higgs Audio v3 TTS 采用约 4B 参数的自回归解码器,基于 Qwen3-4B 骨干网络构建。它支持流式文本输入,可在句子未完整时就开始合成,并在后续文本到达时保持说话人身份、情感和节奏的一致性。音频通过 Higgs Tokenizer 编码为 8 个离散码本,以 25 fps 速率交错处理,最终输出 24 kHz 波形。
多语言表现优异
在 Boson AI 内部的 Higgs-Multilingual 测试集(覆盖 111 种语言和方言)上,模型在 100 种语言上达到个位数 WER/CER。在公开多语言语音克隆基准上同样表现出色,零样本语音克隆仅需短参考音频即可跨语言使用。
| Benchmark | Languages | WER/CER ↓ |
|---|---|---|
| Seed-TTS | 2 | 1.11 |
| CV3 | 9 | 4.41 |
| MiniMax-Multilingual | 23 | 2.74 |
| Higgs-Multilingual | 111 | 3.61 |
通过文本流实现精细控制
开发者可直接在输入文本中插入控制标签,实现情感切换、风格调整、速度音高控制以及音效插入,例如:
<|emotion:amusement|><|prosody:expressive_high|>Wait, wait... <|sfx:laughter|>标签涵盖 20 多种情感、风格、韵律和音效类别,可自由组合。
SGLang-Omni 的多阶段服务架构
Higgs 的生成流程包含多个不同计算模式的阶段,SGLang-Omni 通过阶段抽象、ZMQ 控制平面、CUDA IPC 等技术实现高效调度。AR 阶段使用 OmniScheduler 支持连续批处理与 KV 缓存管理,非 AR 阶段则采用 SimpleScheduler 或 StreamingSimpleScheduler。框架还提供了 CUDA-Graph 友好运行器和流式声码器调度器,使新模型无需重复实现底层优化。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接